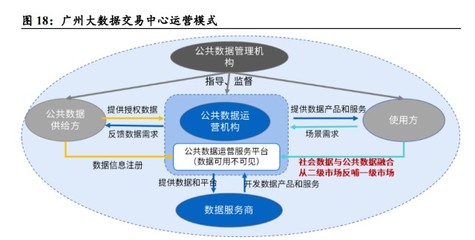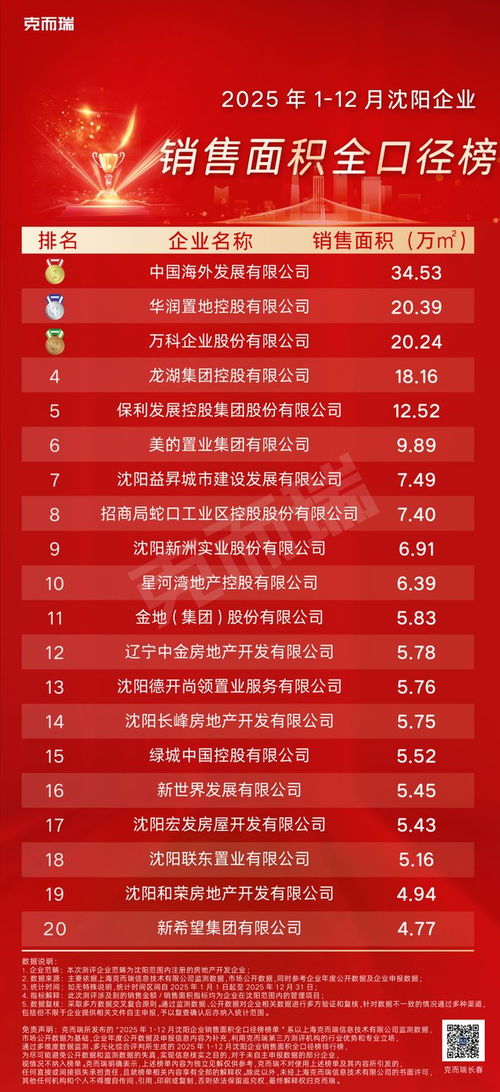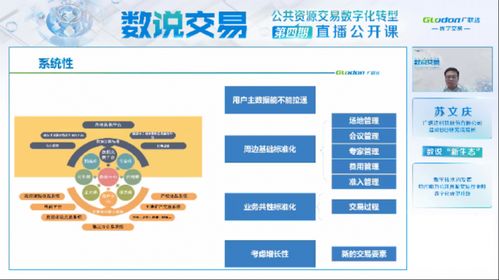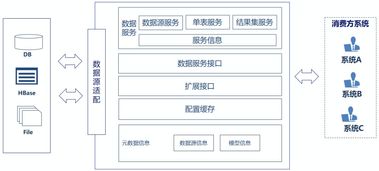
随着互联网业务的飞速发展,数据交易服务的规模与复杂性呈指数级增长。传统的单体JavaWeb架构在面对高并发、大数据量、高可用性等挑战时逐渐力不从心,分布式架构的演进成为必然选择。这一演进过程并非一蹴而就,而是伴随着业务需求与技术发展,经历了从集中到分布、从简单到复杂的清晰脉络。
第一阶段:单体架构与初步解耦
最初的JavaWeb数据交易服务通常采用经典的三层架构(表现层、业务逻辑层、数据访问层)部署在单一的WAR包或EAR包中,运行在一个应用服务器(如Tomcat、WebLogic)上,后端连接单一数据库。这种架构开发简单、部署便捷,适用于业务早期。但随着用户量增长,所有模块耦合在一起,任何微小修改都需要整体发布,系统扩展性差,数据库成为性能瓶颈。此时,演进的第一个信号是引入缓存(如Redis)来缓解数据库压力,并使用消息队列(如ActiveMQ)对耗时较长的非核心交易(如对账、通知)进行异步解耦,这可以视为分布式思想的初步萌芽。
第二阶段:垂直拆分与服务化探索
当单体应用变得臃肿,团队协作效率下降时,垂直拆分(或称功能拆分)成为自然选择。根据业务领域(如用户服务、订单服务、支付服务、数据查询服务、数据上报服务),将庞大的单体应用拆分为多个独立的JavaWeb应用。每个应用拥有独立的数据库,通过HTTP API或RPC进行通信。这一阶段,数据交易服务的核心流程开始被分散到不同的子系统。例如,数据查询和交易下单可能被拆分为两个服务。这解决了团队并行开发和部分扩展性问题,但服务间的调用关系变得复杂,出现了重复代码和分布式事务的挑战。
第三阶段:面向服务的分布式架构
为了治理服务间复杂的网状调用,SOA理念被引入,ESB企业服务总线一度成为中心化的集成方案。更彻底的变革来自微服务架构的兴起。在数据交易服务中,微服务架构将“服务化”推向极致:每个细粒度的服务(如身份验证、费率计算、交易风控、数据加密、清算核心)都作为一个独立的、可自治的Java进程部署。服务注册与发现(如Nacos、Eureka)、配置中心、API网关、分布式链路追踪等组件构成了完整的技术体系。Spring Cloud生态成为Java领域实现微服务的首选。数据层面,数据库按服务彻底拆分,同时引入了更复杂的最终一致性方案(如基于消息的 Saga 模式)来替代传统的强一致性分布式事务,以保障跨服务数据交易的正确性。
第四阶段:云原生与Service Mesh
微服务解决了业务敏捷性问题,但其本身的复杂度(如多语言、通信治理)带来了新的运维负担。云原生理念将分布式架构推向新高度。数据交易服务开始容器化(Docker),并使用Kubernetes进行编排管理,实现极致的弹性伸缩和故障自愈。更为关键的是,Service Mesh(服务网格,如Istio)的出现,将服务间的通信、治理、安全策略(如熔断、限流、重试)从业务代码(Spring Cloud组件)中下沉到基础设施层,由Sidecar代理处理。这使得JavaWeb应用可以更专注于纯业务逻辑(数据交易的核心流程),而将分布式架构的复杂性交由平台统一管理。
第五阶段:演进中的未来:Serverless与数据网格
分布式架构的演进仍在继续。对于数据交易服务中流量波动剧烈的场景(如促销活动),Serverless架构提供了按需运行、按量计费的新可能,开发者可以更专注于函数式代码片段。随着微服务数量的爆炸,数据的一致性与整合成为难题。Data Mesh(数据网格)理念应运而生,它倡导数据领域自治、将数据作为产品来管理,并建立去中心化的数据基础设施。这为未来超大规模、多团队协作的数据交易服务平台提供了架构蓝图,数据的所有权、质量和交付将与业务服务的架构对齐。
**
JavaWeb数据交易服务的分布式架构演进,是一条从单体到微服务再到云原生与数据驱动的持续解耦与能力下沉之路。每一次演进都是为了更好地应对业务规模的增长、提升开发运维效率、保障系统的高可用与高并发能力。其核心驱动力始终是:通过架构的灵活性来拥抱业务的变化**。对于架构师和开发者而言,理解这一演进历程,有助于在技术选型时做出更合理的决策,构建出既能稳健支撑当前业务,又能从容面向未来的数据交易服务体系。